
 微博登录
微博登录
在学习正则之前,一直想写一个综合登录的例子,根据用户绑定的信息,如手机号,Email,用户名来实现高效匹配登陆,根据用户的类型来选择登录的方法。 把整个正则学习一遍,发现正则表达式其实并没有你想像中的那么困难。
C#中 引入System.Text.RegularExpressions命名空间利用Regex.IsMatch(要匹配的字符串, 正则字符串) ,返回bool值来判断匹配结果。
实验1
字符串:him 正则:hi 匹配结果:True
实验2
字符串:
him正则:
\bhi\b匹配结果:False \b表示正则的特殊代码,也叫元字符。 元字符:\b 表示:单词开头和结尾处,不匹配这些单词分隔字符中的任何一个,它 只匹配一个位置。
实验3
字符串:
hi lizhijun正则:
\bhi\b.*\blizhijun\b匹配结果:True 元字符:. 表示:匹配除了换行符以外的任意字符 元字符: 表示:它指定*前边的内容可以连续重复使用任意次以使整个表达式得到匹配 所以,.\表示匹配任意数目除了换行意外任意字符,hi和lizhijun之间有任意长度字符,但hi和lizhijun周围需要一个空格,如:
hi 1 lizhijun True
hi 123 lizhijun True
hi 12 3lizhijun False
hi1 23 lizhijun False实验4
字符串:
010-12111111正则:
0\d\d-\d\d\d\d\d\d\d\d匹配结果:True 元字符:\d 表示:匹配该位置上0-9一个数字 改进: 字符串:
010-12111111正则:
0\d{2}-\d{8}匹配结果:True \d后面的{2}的意思是前面\d必须连续重复匹配2次。 所以{数字} 表示花括号前元字符匹配多少位
实验5
字符串:
1204877922正则:
^\d{5,12}$匹配结果:True {5,12}表示从字符串开始到结束验证\d 5到12次,一般来匹配5到12长度数字的字符串
实验6
表1.常用的元字符代码 说明
.匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束表2. 常用的限定符代码
/ 语法说明
* 重复零次或更多次 重复一次或更多次?重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次字符串:
010-12111111正则:
\(?0\d{2}[)-]?\d{8}匹配结果:True 首先是一个转义字符(,它能出现0次或1次(?),然后是一个0,后面跟着2个数字(\d{2}),然后是)或-或空格中的一个,它出现1次或不出现(?),最后是8个数字(\d{8})。
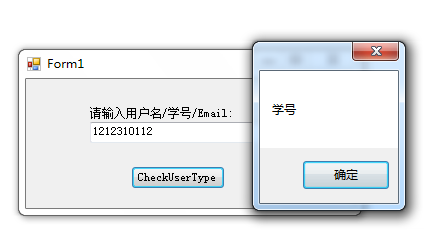
综合实验-桂电学号正则匹配
字符串:
1212310112正则:
^[01]\d12[12345]\d{5}$匹配结果:True 分支条件 正则表达式里的分枝条件指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用 把不同的规则分隔开。 如:一种是三位区号,8位本地号(如010-12345678),一种是4位区号,7位本地号(0376-2233445)。 字符串:
010-12345678正则:
0\d{2}-\d{8} 0\d{3}-\d{7}匹配结果:True
分组
重复单个字符是用{}来表示,如\d{3}重复匹配1-3位上是否是数字,若想重复匹配一组则要用到分组,比如,IP 分组是用()把要重复匹配的部分括起来,再{}指定匹配次数。
简单分组:
字符串:
192.168.001.001正则:
(\d{3}\.){3}\d{3}匹配结果:False 这里的IP必须凑3位 重新写过分组正则: 字符串:
192.168.1.1正则:
^((25[0-5] 2[0-4]\d [01]?\d?\d)\.){3}(25[0-5] 2[0-4]\d [01]?\d?\d)$匹配结果:False 原理:根据分组,IP里4个点分位上的值在0-255,所以分成3种情况 【1】25[0-5] 【2】24[0-9] 【3】第1位可能是0或1或没有,第二位可能是0-9或没有,第三位是0-9 所以分组成: (25[0-5] 2[0-4]\d [01]?\d?\d) 之后的.为什么单独再分一次组是为了节省内部分组重复出现匹配,当然也可以这么写
^(25[0-5]\. 2[0-4]\d\. [01]?\d?\d\.){3}(25[0-5] 2[0-4]\d [01]?\d?\d)$到这里重写验证桂电学号正则表达式: 学号:1212310112 其中:第12位代表入学年,当前只有08,09,10,11,12,13,假定新增有14 第34位代表学校12 第5位代表系别有1-5 第6位为专业代号,各系专业分别[1系8个][2系5个][3系6个][4系6个][5系7个] 第78位为班级代号:假设有6个班 第9、10位位班级第几个同学 正则表达式:
^(0[89] 1[0-4])12(1[1-8] 2[1-5] 3[1-6] 4[1-6] 5[1-7])0[1-6]\d{2}$表3.常用的反义代码代码/语法说明\W匹配任意不是字母,数字,下划线,汉字的字符\S匹配任意不是空白符的字符\D匹配任意非数字的字符\B匹配不是单词开头或结束的位置[^x]匹配除了x以外的任意字符[^aeiou]匹配除了aeiou这几个字母以外的任意字符
例子:\S 匹配不包含空白符的字符串。
<a[^>] >
```匹配用尖括号括起来的以a开头的字符串。
